

Data quality is such a simple concept. Except, it’s not.
We tend to think of it as:
- Bad data = wrong or incomplete data
- Good data = Correct and complete data
But these facile definitions do not reflect the complexity of data quality, notably that bad data can be valid data that gives you answers that seem good but truly aren’t. Here’s a simple example.
Counting the blades of grass in your yard will yield correct data, but it doesn’t tell us when you need to cut your grass. For that, you need different data altogether — the measurement of how high your grass is.
In other words, data is important to us only because it tells us something that we need to know.
Two additional things to consider here:
- It’s not always easy to spot bad data.
- It is VERY easy to create bad data.
Quality Data Powers Insight
To paraphrase Professor Richard W. Hamming’s famous quote, “The purpose of data is insight, not numbers.”
And analyzing data that is not meaningful is misleading, because the data itself may be good, but it doesn’t answer the questions you’re asking. This has enormous implications for missions, business goals, budgets and employees.
To get insight, the data you gather has to be correct, consistent, and fit for purpose — meaning that it is relevant to your data needs.
How Do We Get so Much Bad Data?
To aid in helping us identify, gather, and use quality data, let’s first look at how we wind up with bad data.
Let’s break this down into three categories: collecting, storing and processing.
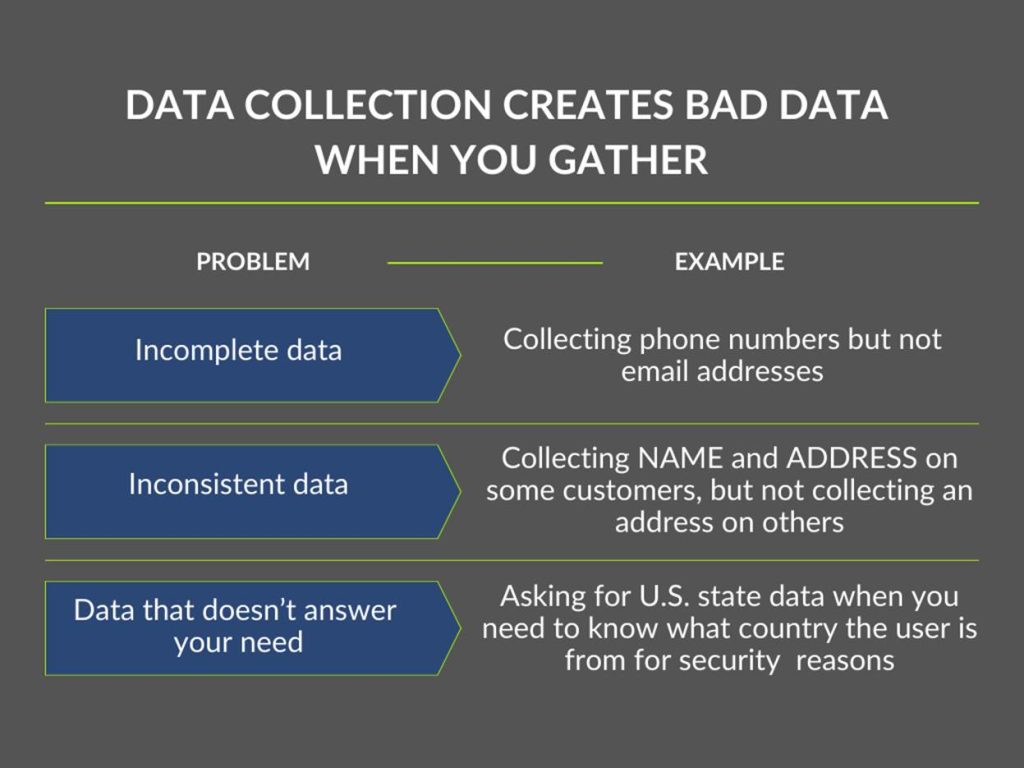
Data collection creates bad data when you gather incomplete or inconsistent, or data that won’t answer your questions or drive the function you need.
Data storage and systems issues cause bad data when you gather data and never touch it again, even as you gather new examples of the same type of data; store identical data in multiple places; have bad system design (e.g., the system doesn’t allow you to query data easily or lacks metadata to help you understand why you have this data); or there are system communication issues.

Processing issues that cause problems include migrating data without verifying its quality or what it’s used for, formatting issues in the new system, and not de-duplicating data.

Every issue we just discussed is influenced by one idea: Data isn’t a one-and-done thing.
What is Good Data, Really?
Good data minimizes how many copies of data are in your system, and is current, maintained, and annotated with metadata.
We often discuss “a single source of truth” but I’ve yet to implement such a thing for a client. The ideal is that each datum is in one central data store that everyone can use for every application. The goal is to break down data silos, or disconnected systems that don’t talk to one another. It’s a great goal, but the reality is more complex, so I’ll say this: Good data is data that does not get duplicated and passed from one system to the next to be used, and ensures “… that the organization provides stakeholders with consistent information throughout time and perspectives”.
Adding metadata to your data helps greatly with this. Metadata is often unhelpfully described as data about data, but it’s really details about data that tell you:
- If the data is important
- How the data is important
- Why the data is important
A simple form of metadata is the names of rows in an Excel sheet.
How Leaders Can Support Tech Groups
The most important thing a leader can do to support data quality is to set aside budget and time for data wrangling and maintenance. To have good data, your teams need to know who owns the data, what it does, what they need to keep for new processes; and have and enforce data governance policies.
Understanding the importance of data quality is paramount for leadership, because without quality data, we cannot make sound business decisions.
Evelyn L. Kent is the owner of Bacon Tree Consulting, a firm that helps clients with digital transformation; systems analysis; validating AI and machine learning models; data forensics; metadata management; text analytics; and building semantic models, ontologies, and knowledge graphs. Evelyn helps organizations find and solve the data barriers that block enterprises from innovation, new markets, and efficient operations. She regularly writes and presents on all things data.



{kind=link}
Leave a Reply
You must be logged in to post a comment.