
Enterprise Architecture portrays technology, data, and people as functional blocks of information. As we know, “architecture” in this context derives from Zachman’s classic article. In the larger context, by definition, modern architecture represents form in terms of function. The same for “pattern.” If I may use a crude abbreviation, a “pattern language” is to “make a building directly from [a} rough scheme of space.” Pattern Language. However, seeing structure and pattern are foiled by change and events. It should be noted that in Heraclitus, the river of change is a change in the observer and the observed. One might say that these metaphors emphasize space rather than time, structure rather than process. Below is a rough alternative.
The function of information technology is to capture the result of an event. The result is represented or embodied, in general, in a transaction or a report. For heuristic purposes here, I would include business intelligence, semantic data, and sensor data. Again, this is only a heuristic statement. The data may be minute, “big,” or a meaningful semantic and graphs. Whether data sources are large amounts, submitted to massive parallel processing, and analyzed with NEW statistical procedures those may result in trivial reports such as the sheer raw number of “tweets.” Users, databases, other machines, sensors are even for minute events, consumers and producers of results. A result belongs to data curators, data stewards, DBAs, developers, and testers.
An economics of information can be seen as the effort and expense required to capture a result of an event. The economic costs versus benefits of information are measured by the significance and meaning, and values of results. The economics of data, seen in a simple way compares the probability that the benefits exceed the costs Good or bad, true or false, a representations of results can come from any size system. Designation of “data at rest” or “data in motion” is a distinction without a difference. Any transactional result is an instantaneous report, and a report is a persistent, but not necessarily permanent and can be seen as representation of a transaction. At any instant, data in motion must rest in order to be converted into new data or information, and data at rest must move in order to capture history, become master data, or be archived.
Data integration is a means of cutting the fat from the lean of information. Too often typical enterprise architecture stack diagrams or matrices portray “data” as sitting between business intelligence and applications as in the Federal Enterprise Architecture Framework (FEAF). The FEAF model reduces data architecture to a storage and management function of applications. The “data” element is supported by applications and technology. In contrast to this, Zachman’s framework gives “Data” a cross cutting importance through all layers. Some Zachman diagrams name this first column “What” and other Zachman diagrams label it “Data.” It is important how data” is depicted” in any ‘stack’ diagram. However, no application is worth more than the result of the data captured. The foundation of systems should be seen in terms of their function, not in terms of a popular sensibility looking for a technology or infrastructure foundation.
No matter how the rest of the application and infrastructural are stood up or configured, the referential integrity and semantic continuity are essential. Representation of where “data” sits or in what “swim lane” it appears, conveys meaning.
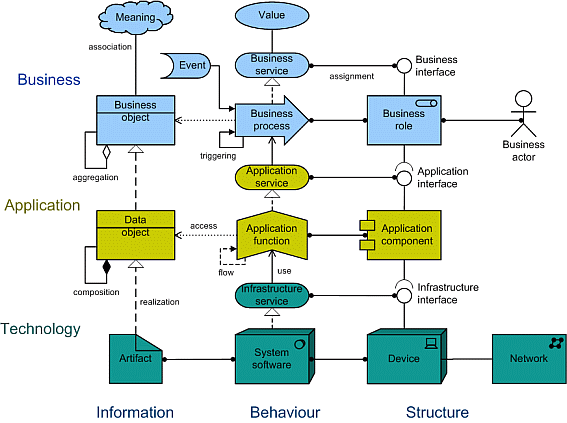
origin unknown, Google Images
This technology stack diagram is pretty good in my view. However, the role of data is minimized in this representation and depicted as supported by the infrastructure, and not as a pervasive, cross-cutting, requirement. Furthermore, the fundamental ground of data is the “semantic layer.” There is no semantic “layer” in a swim lane by itself. Even such robust software development as Domian Driven Development” emphasizes the need to ensure understanding of semantic content of data.
When “glossary” or “vocabulary” is used to attempt to identify data semantics that does not mean that that is a complete or comprehensive or enterprise approach. A “glossary” may capture one or more systems’ meanings without being comprehensive. A canonical environment and semantic layer are foundations of continuity from data collection to analytics with an enterprise scale.
Data-driven, decision-driven, domain-driven, and, even, event-driven architecture explanations try to give structure to events and results. Enterprise architects grapple with these contradictions in the pursuit of form and structure. We would all like to stop time and fix space in order to shape or observe structures of events that produce data. As enterprise architects, we would like to understand the production of data and persist the information results in models, tables, dashboards, maps, reports, statistics, graphs, neural networks, or simulations – and any combination of those and more. No doubt semantic “databases” and graphs are more revealing, but these are not mutually exclusive technologies and resulting information.
The purpose is to make decisions, and the creation of information is itself a result. Information and data are intertwined like a double-helix Making decisions is similar to the “double-helix methodology” in that information and data are analogous to vision and development. The Double-Helix Method applied to (rather than “warfighters), “customers,” “users,” “consumers,” and people who need help. Making decisions is the result that data and information support. There is contact interaction which are events, and are reflexive. The above diagram indicates that by the loop. Decisions are the classic “feedback” found in cybernetics.
Implementing such a complex theory is done easier than thought. Surprisingly, arising from semantics, databases – whether relational, NoSQL, or graph – master data, data warehouse, cubes, business intelligence applications, and the ultimate discovery of information. This means that the technology pay appear obsolete. However, it must made to truly work, and be subject to imagination not complacency. I would contend that the popular configurations of “big data” strategies are parallel or homologous with such an older perspective. Including specific attention to semantics, collaborative requirements collection, and attention to information, not just data, goals. Decisions are results, which are themselves events, which serve rather than dominate.



Leave a Reply
You must be logged in to post a comment.