
| Originally posted to cpsrenewal.ca |      |

Right now the web is awash with articles about Big Data; it seems like everyone is getting caught up in the rush.
I myself even declared that Big Data will become one of the most important policy inputs over the next 10 years (See: Big Data, Social Media, and the Long Tail of Public Policy).
From what I’ve read thus far, Big data seems to be most most effective in systems that are stable over time and abrupt shifts are often to blame when big data goes astray.
For government that means that there could be broad ranging implications for not only large scale changes (e.g. the cancellation of the long form census) but also smaller changes in methodology (or even phraseology) that breaks up data that could otherwise be used in longitudinal studies (e.g. changes to the questions asked in Public Service Employee Survey between 2005 and 2008).
As governments inevitably learn more about the importance of Big Data they may find that decisions made in the past – even those made by past governments or long retired bureaucrats – that were originally thought to be relatively straight forward may actually have had a number of unanticipated consequences.
Therefore in the interim, current governments (and their bureaucrats) may want to consider to stay the course with current data collection efforts, ensure any new data mining (surveying) is backwards compatible and avoid locking data into proprietary systems that are not likely to age well.
But big data is not, as they say about every new thing that is expected to eventually make it big, a panacea
Or, as a recent article at the New Yorker’s blog put it:
Some problems do genuinely lend themselves to Big Data solutions. The industry has made a huge difference in speech recognition, for example, and is also essential in many of the things that Google and Amazon do; the Higgs Boson wouldn’t have been discovered without it. Big Data can be especially helpful in systems that are consistent over time, with straightforward and well-characterized properties, little unpredictable variation, and relatively little underlying complexity.
But not every problem fits those criteria; unpredictability, complexity, and abrupt shifts over time can lead even the largest data astray. Big Data is a powerful tool for inferring correlations, not a magic wand for inferring causality.
In other words, Big Data can help policy makers better formulate their options, not make their decisions for them. I think it is worth quoting the New Yorker further:
As one [skeptic put it], Big Data is a great gig for charlatans, because they never have to admit to being wrong. “If their system fails to provide predictive insight, it’s not their models, it’s an issue with your data.” You didn’t have enough data, there was too much noise, you measured the wrong things. The list of excuses can be long.
The quotation shows what is likely the introduction of ‘data quality’ as a likely scapegoat for poor or unpopular decisions and drives home the importance of data literacy for not only bureaucrats and politicians but also for citizens.
That said, what the quotation fails to address (likely by design, as it wasn’t written specifically for a public policy audience) is the fact that the introduction of more complex data may actually increase decision gridlock by creating paralysis by big data analysis.
For example, what happens in the inevitable case where big data fails to paint a clear path forward but citizens continue to press for action?
Make no mistake, this is not a hypothetical problem, but rather likely one of the first problems to follow on the heels Big Data becoming a substantial policy input.
To date, (and correct me if I’m wrong) much of the public sector data discussion, and by extension the appification of government services built thereon, has focused mainly on alternative or augmented service delivery models, not public policy development. In a previous post I addressed how data abundance could impact government policy (again, see: Big Data, Social Media, and the Long Tail of Public Policy but given what has been laid out above and the length of the aforementioned article, it bears both repeating and concluding with:
As a starting point, bureaucrats can anticipate a renaissance of the language of data driven decision making within the larger nomenclature of evidence based policy making. Make no mistake, these terms are still very much in vogue in bureaucratic culture but likely require a fresh definition given that the nature of what underlies them – namely the availability of detailed data, and as a consequence analysis – will improve significantly over the foreseeable future. As a conceptual framework, it would look something like this (click to enlarge):
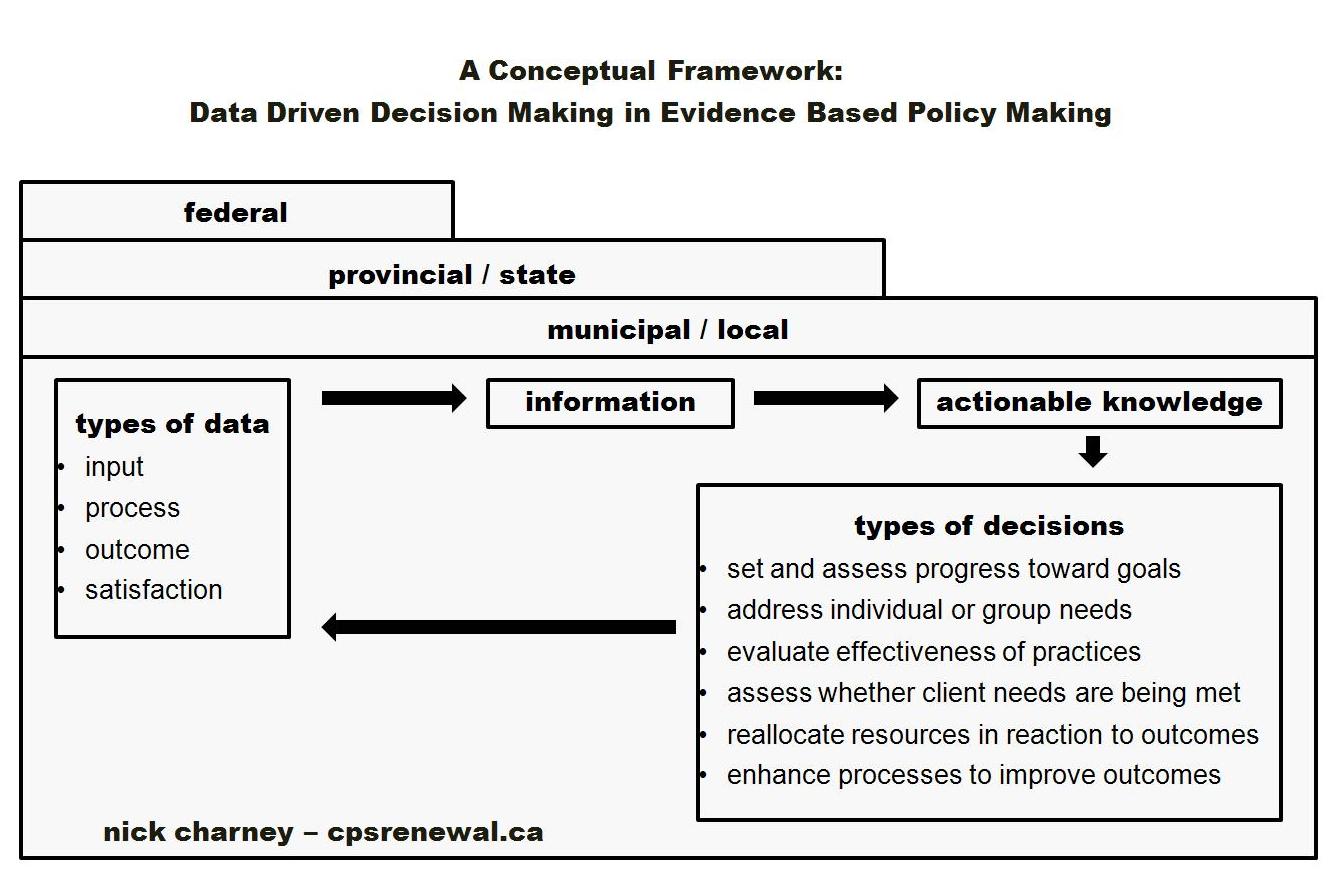
Note that the framework recognizes that data driven decision making must be understood within a larger context. In this type of environment, policy makers will need to consider the types of data being collected, the analysis being performed and decisions being made across all levels of government: municipal, provincial, and federal. Under this type of model, there is a significant probability that analysis will expose untenable points of in-congruence between the highly contextual and specific insights pulled from the intersecting data points and governments’ tendency to pursue universal, one-size-fits-all, policy solutions. In other words, providing policy makers with a deeper understanding of the complexity of a particular public policy challenge is likely to yield equally complex public policy solutions.
That is, after all what we – politicians, civil servants and citizens – are after, isn’t it?



Leave a Reply
You must be logged in to post a comment.