
This weekend I attended the rather fantastic Open City Workshop in Edmonton, Alberta, Canada. If you don’t know much about what’s happening in Edmonton, you should probably check out Adriel Hampton’s recent post on the critical mass for awesomeness that’s happening there. There’s a innovative team at work in Edmonton which is a great model for opengov partnerships everywhere.
Open City Workshop Edmonton was so good, in part, because of the multimedia commentary that accompanied the panel an discussion. Many, including myself, participated in both the on-location discussion and the #openyeg Twitter discussion. For myself, there is no way to separate the two.
There was some talk after the conference as to how we could capture the Twitter stream, so that we didn’t lose this important discussion, which had a profound and positive impact on the conference proceedings. In the days of the rapid response internet, ask and you shall receive.
Mark Traphagen an Internet Marketing Analyst at Virante.com has written a great post on using Google Reader to archive conference tweets.
“In fact, a conference Twitter stream may be so valuable that you’d like to save it and be able to refer back to it later. Google Reader, Google’s RSS feed reader that’s oh so much more, makes it very easy to do just that. Here’s how (prerequisite: a Google account that you’re
logged in to:
- Go to search.twitter.com and search for the hash tag associated with the event you want to archive.
- The results page for any Twitter search is automatically an RSS feed. Right-click and copy the feed link.
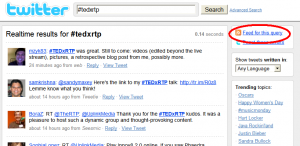
3. Go to Google Reader and click the “Add a subscription” button at the upper left
4. Paste the feed URL you copied in step 2 into the Add box and click “Add.”
You now have a complete archive of the Twitter stream for your conference hash tag. Even better, Reader will automatically update this archive with any new tweets using the hash tag…forever!”
I used this technique to archive the #openyeg tweets and then retweeted a link to the how to on Twitter itself. I’m a strong advocate of using the tools to share the tools.



To add to this, many people…especially agencies…want to export that tweetstream to a permanent XML file which they can post to their own site as an archive…or for other reasons.
To export the stream of tweets, from everything that Google Reader has, simply click on the feed you want to export within Google Reader, then copy the URL at the top and modify it like so:
From:
https://www.google.com/reader/view/?tab=my#stream/feed%2Fhttp%3A%2F%2Fandrewpwilson.posterous.com%2Frss.xml
to:
https://www.google.com/reader/atom/feed%2Fhttp%3A%2F%2Fandrewpwilson.posterous.com%2Frss.xml
Great post, Bowen. Thanks for sharing this process.
This is one of my favorite topics…in fact, it verges on an obsession. 🙂 Last year after the Open Government and Innovations conference in Washington, DC, a few of us were sitting around saying that we should create a “Tweetbook” of the event…so I posted the idea on GovLoop…and a week later we produced the OGI Tweetbook.
Some of the challenges that we encountered:
1. Took 7-8 people to pull this off…a lot of manual labor.
2. Needed an elegant way to reverse the stream…Yahoo! Pipes doesn’t work consistently.
3. Twapper Keeper performs a similar function to Google Reader…but it doesn’t continue to pull the stream and it doesn’t allow you to download and produce something akin to a tweet book with all the formatting.
4. TweetDoc pulls all the tweets into a nice book…but limited you to 500 tweets.
A couple questions about Google Reader:
– Does it flip the stream and put it in real chrono order?
– Does it retain the formatting so that you can pull images for the purpose of including in a “Tweet Book”
I can’t believe a developer hasn’t produced something that allows you to quickly flip the tweet stream and display it in an attractive way….I’d put up some of my own money to make it happen!
Thanks again.
Good stuff. Added this to the How-To section on GovLoop…
I’ve tried this in the past, but have sometimes noticed that my Google reader was not getting all of the tweets. I’m not sure if the situation has improved since then.
Another option is to set up in advance a “Twapper Keeper” for te hashtag for your event.
Thanks for posting this. I’m the author of the original post that Bowen is reproducing here. I’ve since updated the middle with a technique to get ALL of the hashtagged tweets into Reader if you’re starting your feed after the hashtag already has a lot of Tweets.
(Alternative, but recommended: Go to TwapperKeeper.com and create an archive for your hashtag. Advantage: the TwapperKeeper feed will pull all of the tagged tweets into Reader, whereas the direct RSS from the Twitter search will only pull in about 25-30 of the most recent Tweets. Once the TwapperKeeper archive is generated, right click on the RSS Feed link and copy its URL.) Then use that URL for the subscription in Reader.
In addition to grabbing the tweets, when I see a great conference in areas I’m interested in, I want to add those folks to my contacts on Twitter. The easiest way I’ve found is to use TweepML and just load successive search page links to build a new list. It will of course grab everyone using the tag, not just attendees, but for a quick and dirty list, it’s invaluable.
Then you can follow with just a click or two. Haven’t seen quite as simple a way to build a list on Twitter (if you don’t want to follow everyone), but I’ve done that manually and there are plenty of hacks for speeding up that process as well (like using a dummy account to follow all, then adding everyone from that list).
Here’s the list I built for the Edmonton Open City event.
Just stumbled upon this post.
Andrew – to confirm, TwapperKeeper DOES continue to pull the stream after it is created.
It first tries to reach back as far back as the search API allows [1500, 7-10 days] and then pulls data directly from the twitter streaming api going forward (it used to constantly pull from search api with the same desired effect, but now it is more reliable).
If you have any issues, let me know.
p.s. I have been considering a “nice output” but haven’t had too many requests for it. Will think about adding to the system.
John
http://twapperkeeper.com
http://twitter.com/jobrieniii
http://www.linkedin.com/in/jobrieniii